Most MCP servers today are built like vending machines: press a button, get one item. If you need five items, then you need to press five buttons in sequence, juggle the intermediate results yourself, and hope you don't run out of hands. This is a problem, and it's getting worse as the volume and adoption of MCP Servers scale.
These tools should be more like specialized teammates you can hand off work to, with the orchestrator agent serving as a generalist, ie: I propose that MCP servers should be agents in disguise. A server should expose only simple, high-level tools (at the level of business logic) while internally handling the complex, multi-step logic that the MCP client would otherwise have to implement itself.
I built Canvas MCP, which saw over 2000 unique users at its peak during finals season. It is wrapping Canvas LMS (the most popular platform used by US universities for distributing assignments and course materials). It worked great, it could find resources and answer student queries, but it had a big problem.
Hierarchy Traversal is Eating Your Context Window
The Model Context Protocol suffers from tool sprawl. As Anthropic's own engineering team recently wrote in this blog:
As MCP usage scales, there are two common patterns that can increase agent cost and latency: (1) Tool definitions overload the context window; (2) Intermediate tool results consume additional tokens.
Many real-world services like Google Drive, Linear, Notion, GitHub and even Canvas LMS organize data in deep hierarchies. Workspaces contain Projects; Folders contain more Folders; and some Folders contain files. So far, the frontend and REST APIs have been built around navigating these trees, and they worked pretty well. However, when it came to making MCP servers, they decided to mirror that structure: one tool per level of the hierarchy.
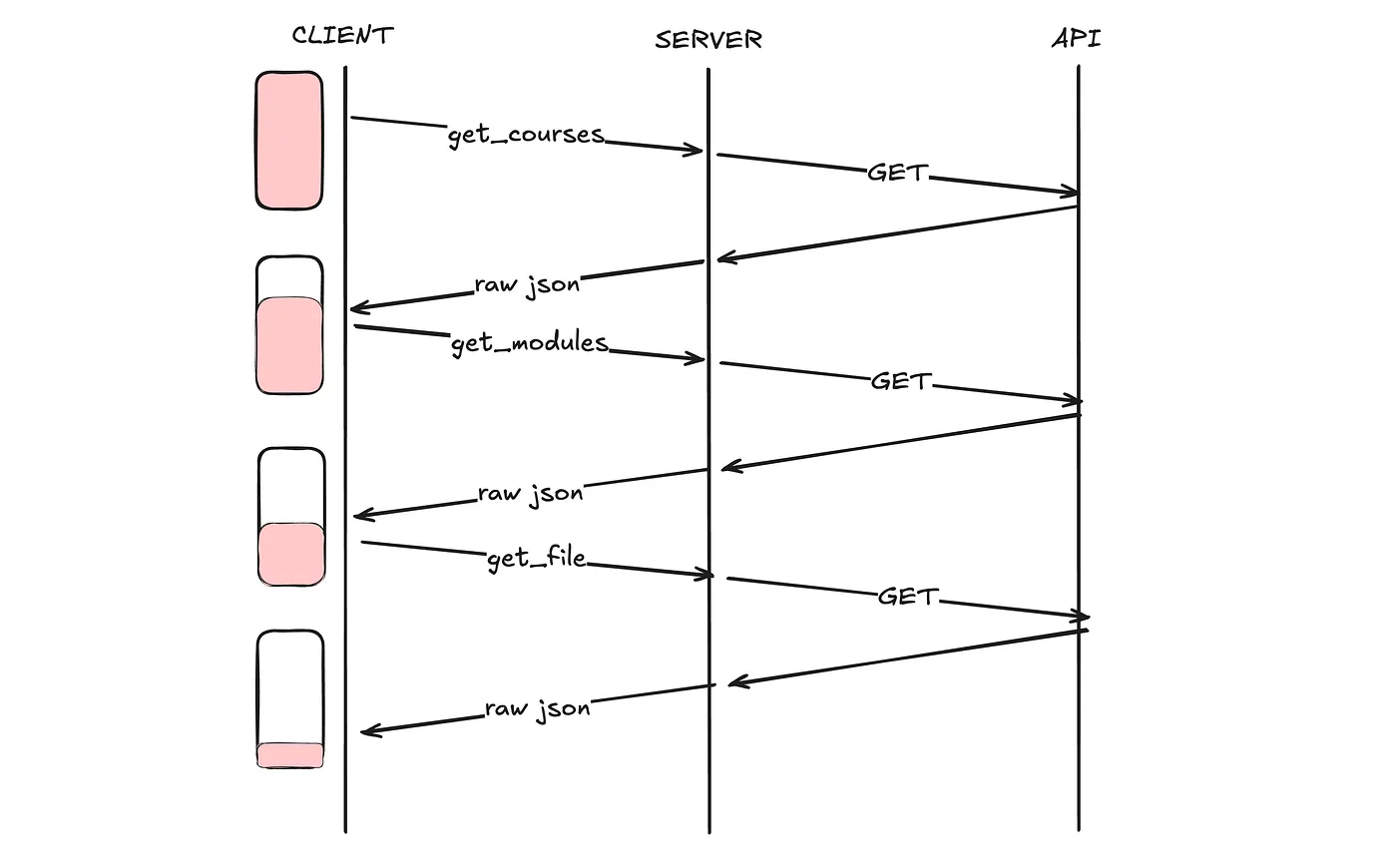
This means that to accomplish a simple task like "find the syllabus for my Linear Algebra class," an MCP client has to:
Call
get_courses→ receive a list of all coursesParse the response, find the right course ID
Call
get_modules(course_id)→ receive all modulesParse, pick the likely module
Call
get_module_items(course_id, module_id)→ receive all itemsParse, find the file
Call
get_file_url(course_id, file_id)→ finally get what you wanted
That's 7 round-trips on your client, and 7 API calls on the MCP server at minimum, often more if the client fetches the wrong module. Every intermediate response gets dumped into the context window. The client agent processes everything, extracts one ID, and moves on. Most of those tokens are wasted in the context history.
There are solutions, like Claude Code just shipped MCP Tool Search because connecting 5–6 MCP servers was consuming 30–50% of the context window before you had even typed a prompt. Cloudflare published Code Mode and found that having LLMs write code to call MCP tools instead of calling them directly reduced token usage by 81%.
These are excellent architectures, but what if we inverted this? Instead of making the client smarter at navigating dumb tools, we make the server smarter and give the client simpler tools.
Therefore, this post explores a different approach: MCP servers should be agents in disguise. Instead of exposing a hierarchy of granular operations, an MCP server should accept high-level natural language intents, do the work internally, and return the final result. The orchestrating LLM shouldn't have to micromanage the traversal of your data model.
Case Study of Canvas MCP
When I first built the MCP server, I did what everyone does. I mirrored the REST API. Each level of the hierarchy became a tool: get_courses, get_modules, get_module_items, get_file_url, get_course_assignments, etc_._
Claude could navigate the hierarchy, find things, and answer simple questions. It worked, but it was unbearably slow due to 2x round-trip latency, and it consumed so many tokens in the orchestrating LLM that it couldn't be used for any other task.
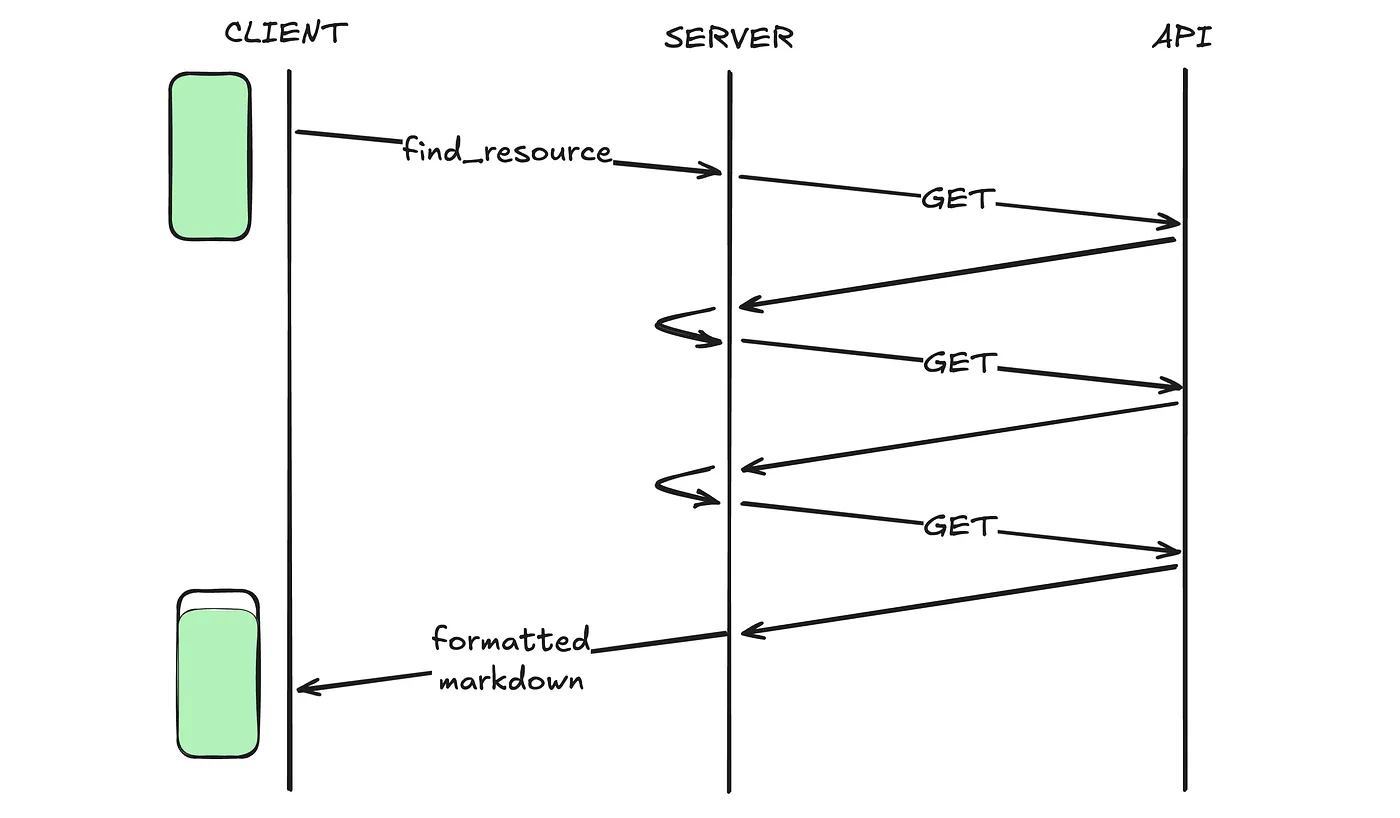
So, I built a second version of Canvas MCP. Same Cloudflare Worker, same Canvas API underneath, but instead of 15 granular tools, it exposes only 3 which take natural language inputs:
find_resources — "Find the syllabus for my algorithms class"
find_assignments — "What's due this week across all my courses?"
course_overview — "Give me an overview of CSE 450"
Beneath each tool call, there is a cheaper agent powered by Kimi K2 that receives the natural language query and has access to the same Canvas API functions as the original server. The agent decides which courses to search, which modules to drill into, and which API calls to make. It performs the traversal internally, synthesizes the results, and returns a well-formatted summary.
I deployed both versions and ran them against the same queries. The results were certainly more dramatic than I had expected.
All of the code, raw data and model outputs are available on GitHub at https://github.com/aryankeluskar/canvas-mcp/tree/master/blog
Trade-Offs
As the data shows, this pattern works less well in three scenarios:
(1) When intermediate inspection matters: some debugging agents need to see the shape of the data at each step instead of the final result.
(2) When latency on trivial queries is critical: adding an internal LLM call adds 500–2000ms, which feels sluggish for "show me course X" queries that were single API calls before. This problem will get less significant as we get more efficient ways of LLM Inference, like Taalas HC1 achieving 16k+ tokens/sec.
(3) When fine-grained client control is required: some workflows need human-in-the-loop decisions at each layer of the hierarchy. For these cases, encapsulating traversal inside the server removes agency the client genuinely needs.
Another big decision is who bears the LLM cost? In the traditional MCP model, the client pays for all reasoning tokens. In the "agent in disguise" model, the server now incurs its own LLM costs. While this can be minimized by using the cheapest model capable of accurate tool-calling, there's a better way to tackle this. The server could bill the client per tool-call, where client pays less for reasoning tokens, but pays a different party (the MCP server) for its specialized intelligence.
Conclusion
The MCP ecosystem is maturing. It was donated to the Linux Foundation in late 2025. As the protocol standardizes, MCP servers will be differentiated not just by the quantity of tools they expose but by how intelligent they make the client.
The servers that will win aren't the ones with the most tools. They're the ones smart enough to do more with less.