tl;dr: Memory hierarchy and memory transfers are the primary constraints in modern GPUs (not compute power), and
torch.compilesolves it by fusing operations and reusing global buffers. It offers computation amortization, where the first invocation will take time to compute the computation graph, memory planning, etc, but subsequent invocations and inference will be lightning fast.
Machine learning models are solving some of the world's most complex problems by running billions of calculations, yet they often struggle on high-performance GPUs. Most efforts to speed up inference focus on increasing compute and bandwidth, but the bottleneck rests with the eager execution problem.
We often observe models running slowly despite executing on high-performance GPUs. 'Eager Execution' basically means that instructions are executed as they are fetched instead of fusing or combining them, ie: each math operation is individually fetched from the memory and then individually handed to the GPU. Each matrix multiplication, activation, and normalization launches a new kernel separately. For example, in a 32-layer model with 100 operations per layer, each forward pass triggers 3,200 separate kernel launches, which count towards the latency and speed of inference.
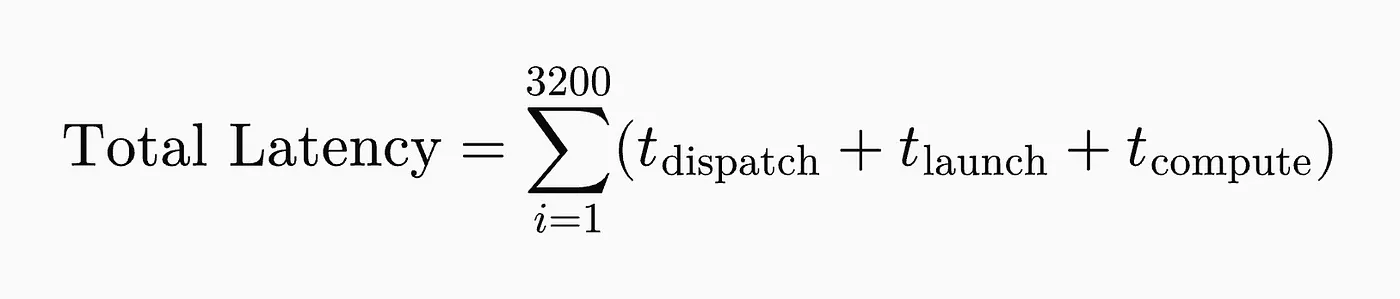
Therefore, the total latency skyrockets. But what is the REAL constraint? Memory hierarchy. That's the reason eager execution becomes a bottleneck and doesn't let the GPU utilize its compute power to the fullest.
Modern GPUs, like the Nvidia H100, achieve 300+ TFLOPs of compute, but they are limited to ~3 TB/s memory bandwidth because memory transfers are computationally very expensive, causing eager execution to fail at scale. Each eager-mode operation performs atleast three separate memory transfers:
- Read input tensors from VRAM
- Write intermediate results to VRAM
- Read weights from VRAM
Even a simple sequence like x = torch.relu(torch.matmul(a, b) + c) requires atleast six memory transfers (read a, b, c (one by one), write matmul result; read that result; and write final output). This memory traffic saturates the memory bandwidth, resulting in the GPU cores being underutilized.
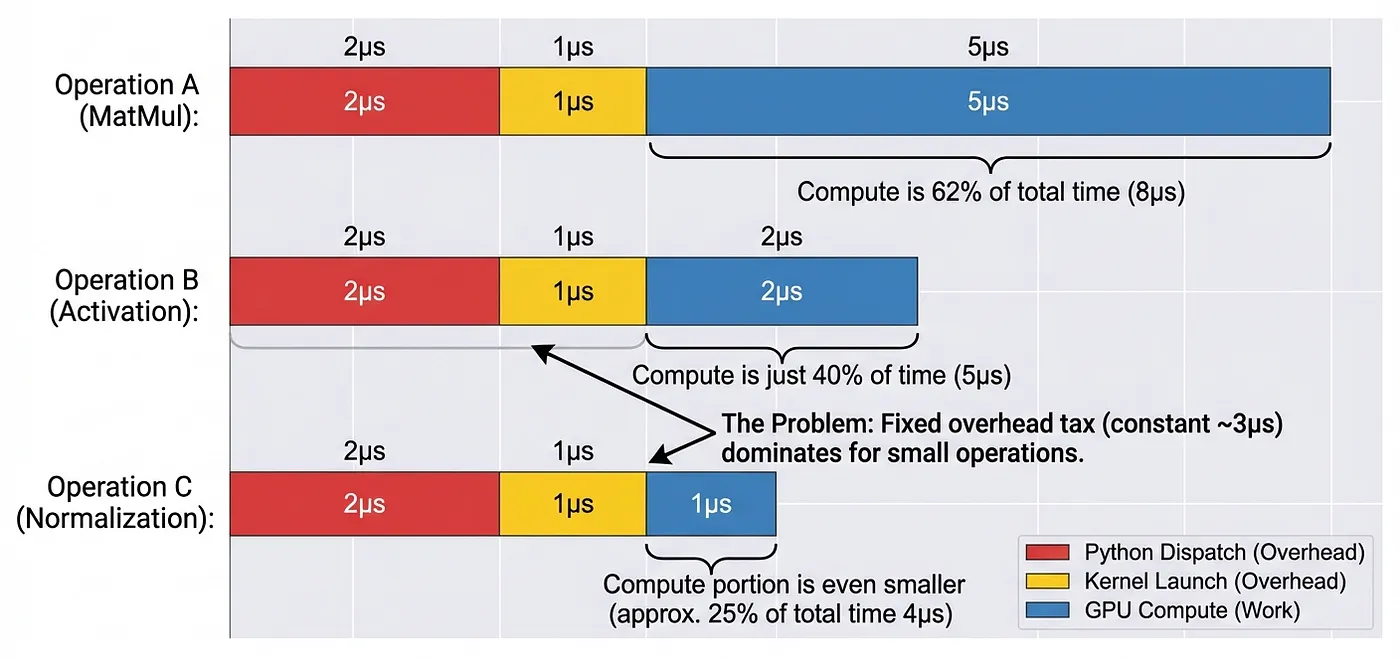
Eager execution breaks at scale because independent operations cannot fuse memory transfers, which creates redundant VRAM accesses.
In production deployments where the CPU serves thousands of concurrent requests, it may spend more time in PyTorch's dispatcher than on launching useful compute, severely limiting the throughput of the model.
Computation Graphs
torch.compile aims to eliminate this exact per-operation overhead by capturing the entire computation graph ahead of time. This computation graph consists of two primary components:
- TorchDynamo: A Python just-in-time compiler that intercepts bytecode execution
- TorchInductor: A backend that generates optimized Triton kernels for GPUs and C++ for CPUs
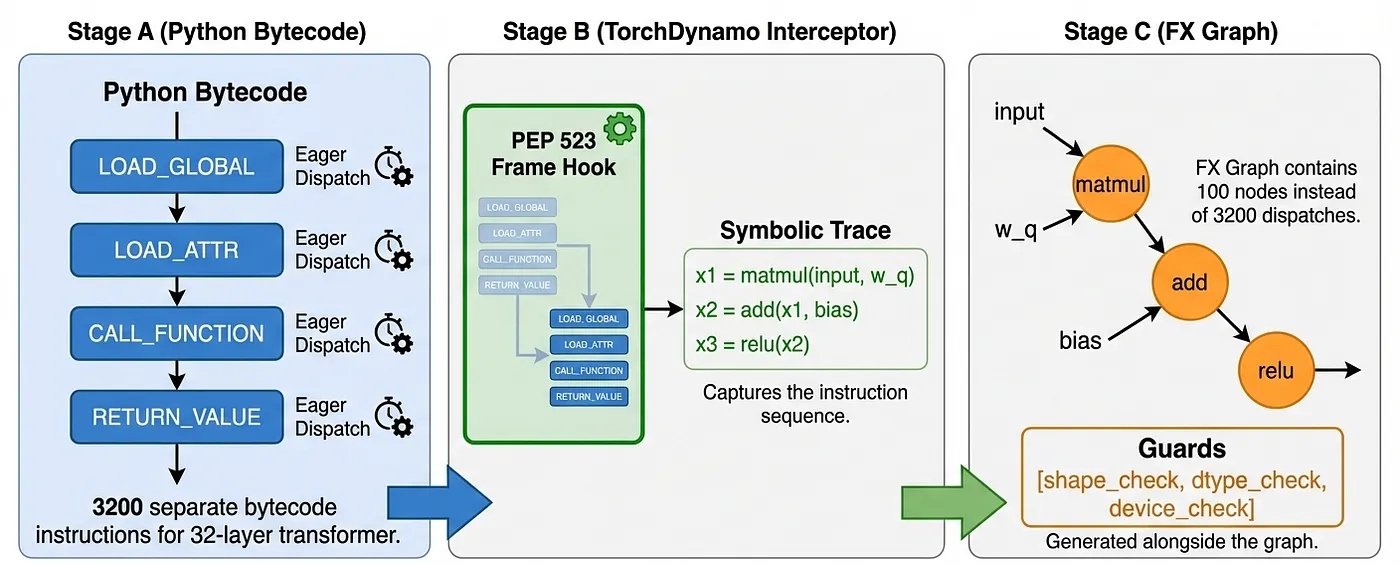
In PyTorch specifically, this computation graph (seen in Stage C) is called an FX Graph, which represents operations as nodes in a directed acyclic graph (DAG). When torch.compile is invoked, TorchDynamo analyzes the Python bytecode to create an FX graph where nodes represent tensor operations and edges represent data dependencies.
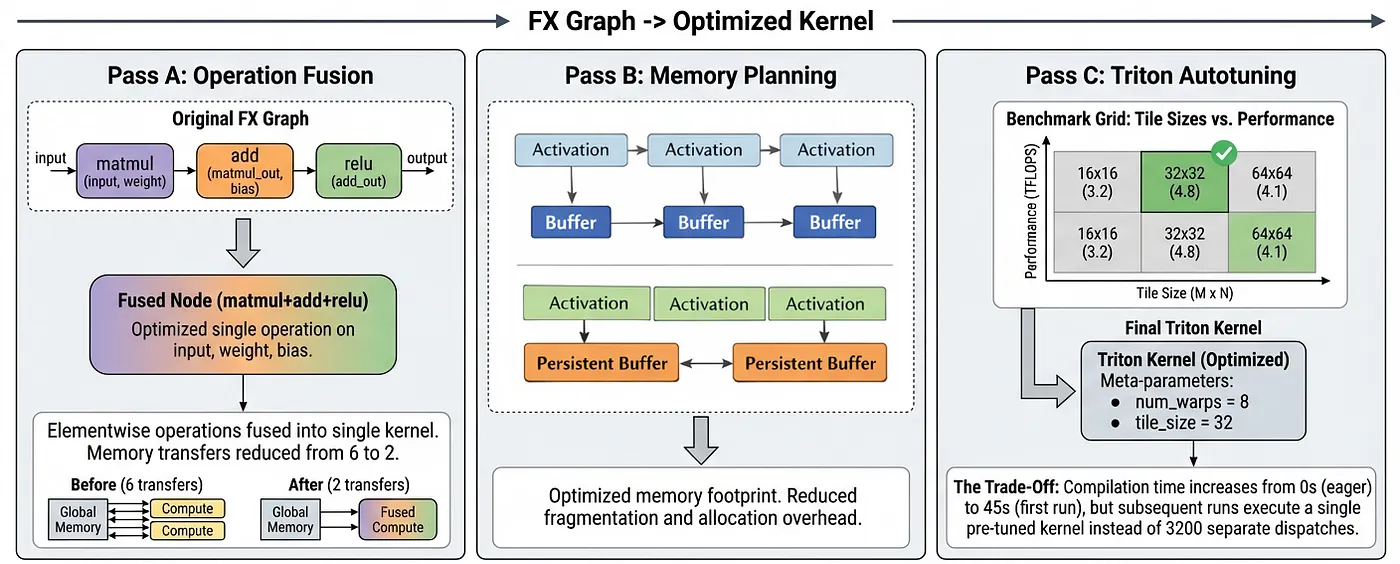
Then, TorchInductor applies three key transformations: Operation Fusion, Memory Planning, and Triton Autotuning, as shown in Figure 3.
1. Operation Fusion
Let's go back to our earlier example of x = torch.relu(torch.matmul(a, b) + c). In eager mode, this can require six VRAM transfers. TorchInductor fuses these into a single Triton kernel that:
- Loads tiles of a, b, and c into on-chip SRAM (shared memory)
- Computes matrix multiplication on registers
- Applies the addition and ReLU while data remains in registers
- Stores only the final result back to VRAM
This reduces memory transfers from 6 to just 2, resulting in a 3x reduction in memory transfers needed to perform the same operation.
2. Memory Planning
Instead of allocating fresh memory for each intermediate, TorchInductor overlays buffers whose lifetimes don't overlap. TorchInductor uses memory planning and buffer reuse to allocate a single pool of memory that gets overwritten by non-overlapping intermediate activations, similar to how a compiler reuses registers. This basically creates a global buffer reuse across the computation graph, making it particularly helpful for transformer-based models with irregular activation patterns. Another benefit of memory planning is to reduce the peak activation memory footprint, which can enable larger batch sizes.
3. Triton Autotuning
Simply put, Triton Autotuning automatically discovers optimal kernel configurations, such as the ideal tile sizes, thread block dimensions, and pipeline depths, for your hardware device and input shapes.
Results
On first invocation, compilation may take several minutes for large models. But, subsequent invocations load precompiled kernels in just a few milliseconds. So, that initial overhead is amortized across future invocations, making computation graphs ideal for production inference, where the model runs continuously. While the initial cold start takes longer, the inference speed for all subsequent requests is significantly higher.
PyTorch's official benchmarks show substantial gains across 165 types of machine learning models, including transformers, CNNs, and diffusion models. torch.compile, on average, provided a 20% speedup at float32 precision and a 36% speedup at automatic mixed precision (AMP).
All while making torch.compile straightforward and easy to integrate.
import torch
# For a model
model = YourModel()
compiled_model = torch.compile(model)
# Or for a function, also enables Triton autotuning
@torch.compile(backend="inductor")
def forward_pass(x, weights):
return torch.relu(torch.matmul(x, weights))
output = compiled_model(input_tensor)That's pretty much a big picture of how torch.compile uses multiple smart techniques under the hood to achieve speedups with minimal code changes. Instead of relaunching kernels for each operation and using naive memory transfers, we launch a single kernel to handle multiple operations using a shared memory buffer. That's how we can reduce the impact of memory bottlenecks and achieve higher utilization of modern GPU compute power.
I was fascinated by the universality of the speedups I was getting at inference time. Computation graphs work not just for large-language models but also for smaller neural networks. Almost every time I asked Cursor or Claude Code to optimize my inference pipeline, the first thing it would do is use torch.compile. This got me curious about how the mechanism works that slowly turned into a rabbit hole, which I hopefully explained well in this blog :)